图形面板
前文我们介绍了 Grafana 中的面板概念,对于基于时间的折线图、面积图和条形图,我们建议使用默认的时间序列进行可视化。接下来我们就来介绍基于 Time series 时间序列的图形可视化方式的操作。
数据源
在创建面板之前我们需要指定我们的面板数据来源,也就是数据源,Grafana 支持多种数据源,我们这里当然使用 Prometheus 作为数据源来进行说明。在 Grafana 左侧工具栏选择 Configuration,点击到下面的 Data sources,打开添加数据源的页面:
点击页面中的 Add data source 按钮开始添加数据源:
选择第一项 Prometheus 数据源进行配置:
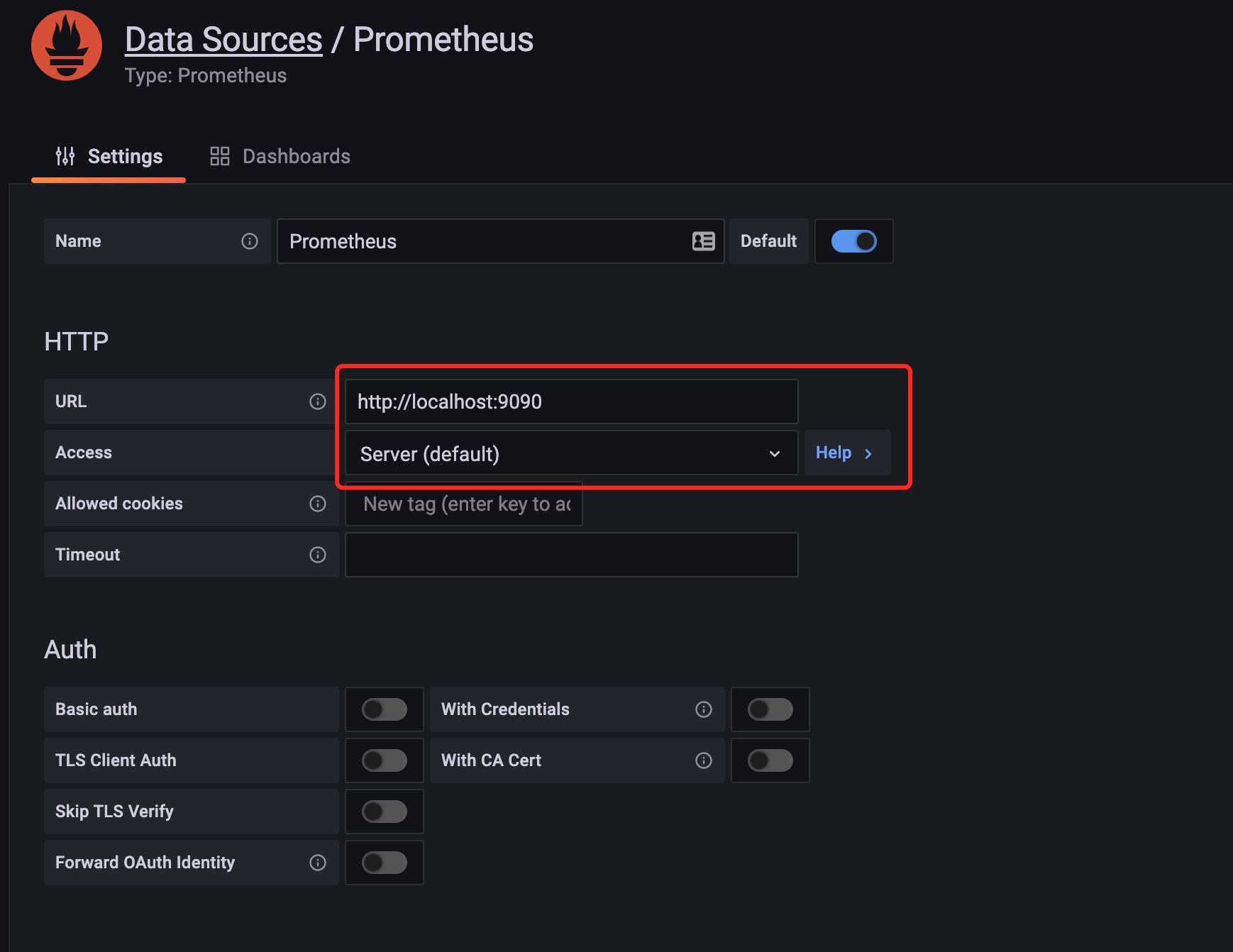
在 HTTP 项中配置 URL 地址为 http://localhost:9090,其实就是 Prometheus 的地址,由于我们这里 Grafana 和 Prometheus 都在同一个节点上,所以用 localhost 即可访问,当然用 IP 也可以,Access 选择默认的 Server 代理方式,这样就相当于 Grafana 程序去访问 Prometheus 而不是在浏览器端去访问,如果 Prometheus 配置有认证,则还需要在下发配置 Auth 信息,配置完成后,拉到最下方点击 Save & test,提示添加成功即表面数据源添加成功了。然后在数据源列表中就会出现我们刚刚添加的 Prometheus 这个数据源了:
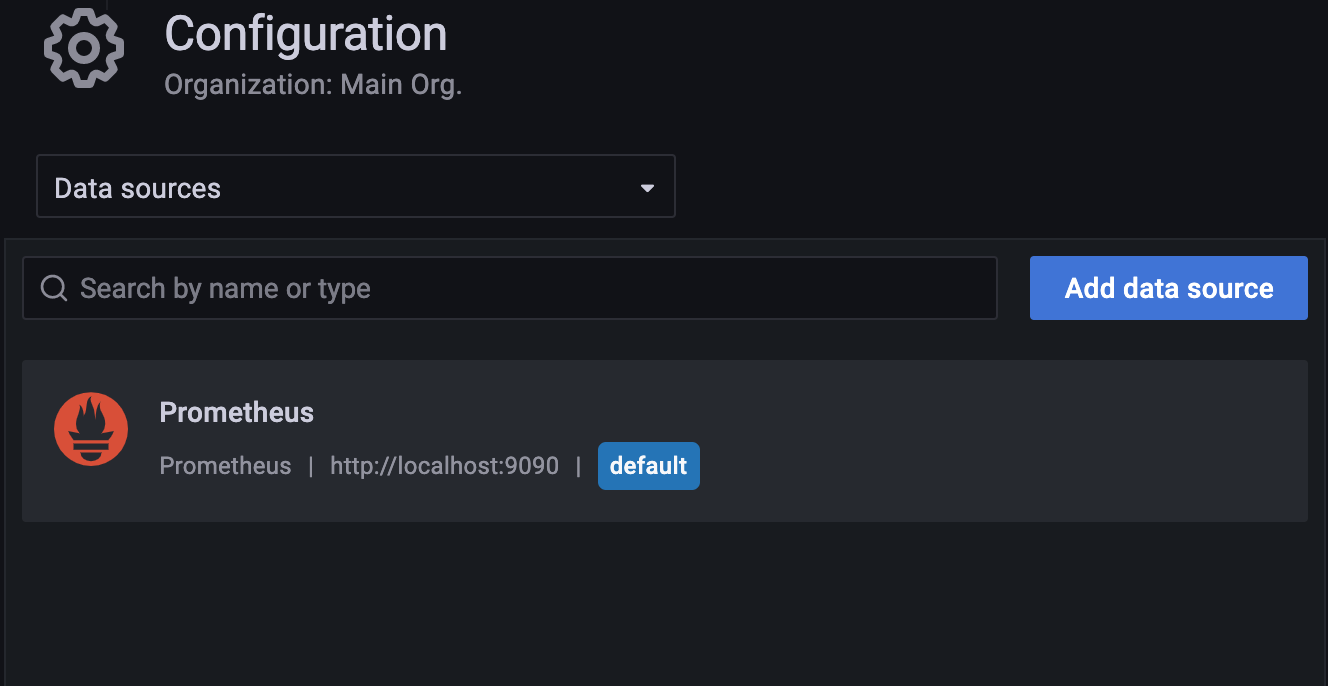
如果想要添加其他支持的数据源则也可用同样的方式进行添加。
添加面板
面板是属于某一个 Dashboard 的,所以我们需要先创建一个 Dashboard,在侧边栏点击 + 切换到 Dashboard 下面开始创建 Dashboard:

在默认创建的新的 Dashboard 中就有一个空的面板,点击 Add an empty panel 即可开始添加面板:
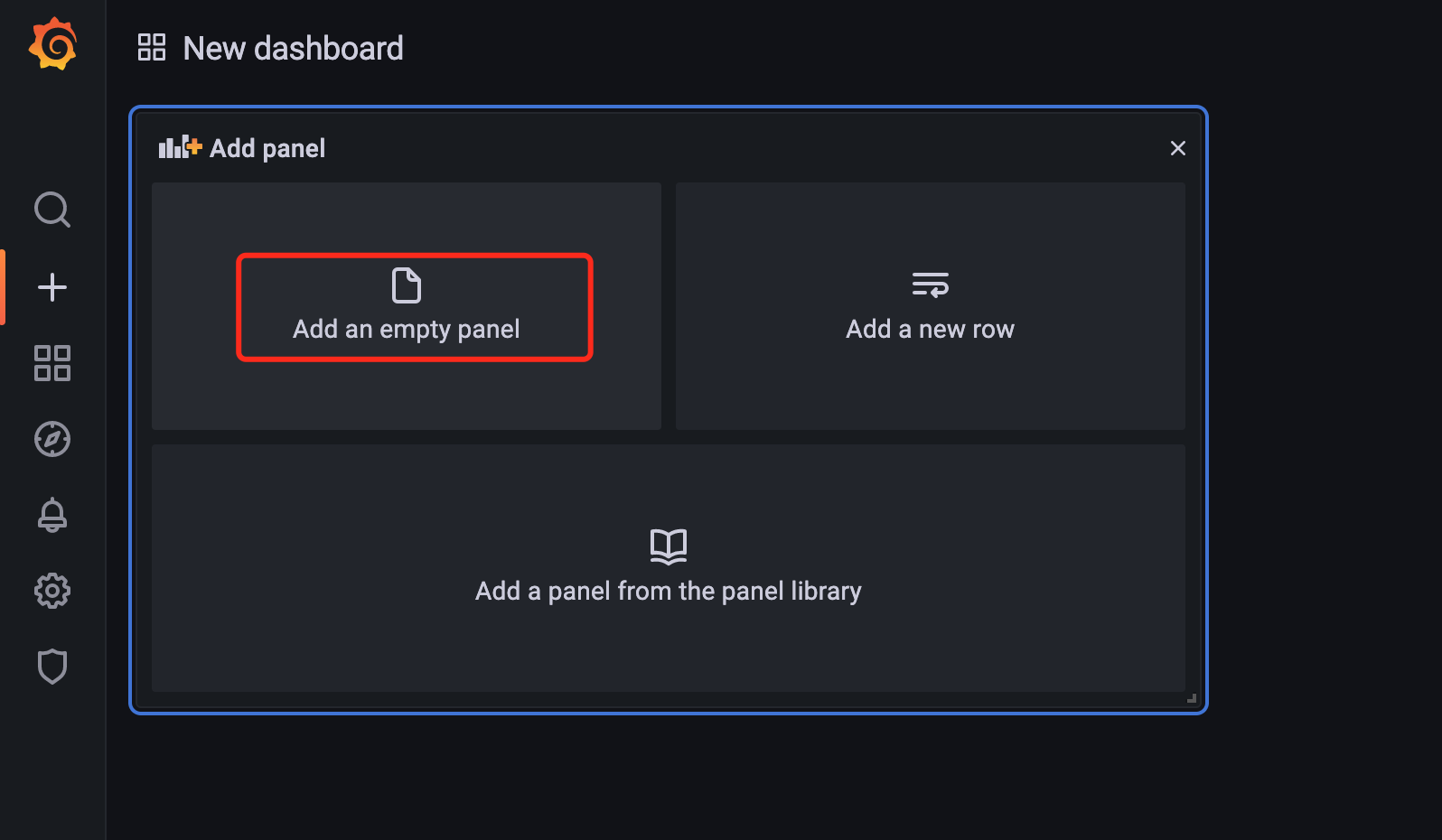
进入面板编辑器后即可添加面板了,中间位置是查询语句的显示结果,下方是用于配置查询语句的地方,左侧可以选择面板显示的类型,面板元信息,比如标题、描述信息等。
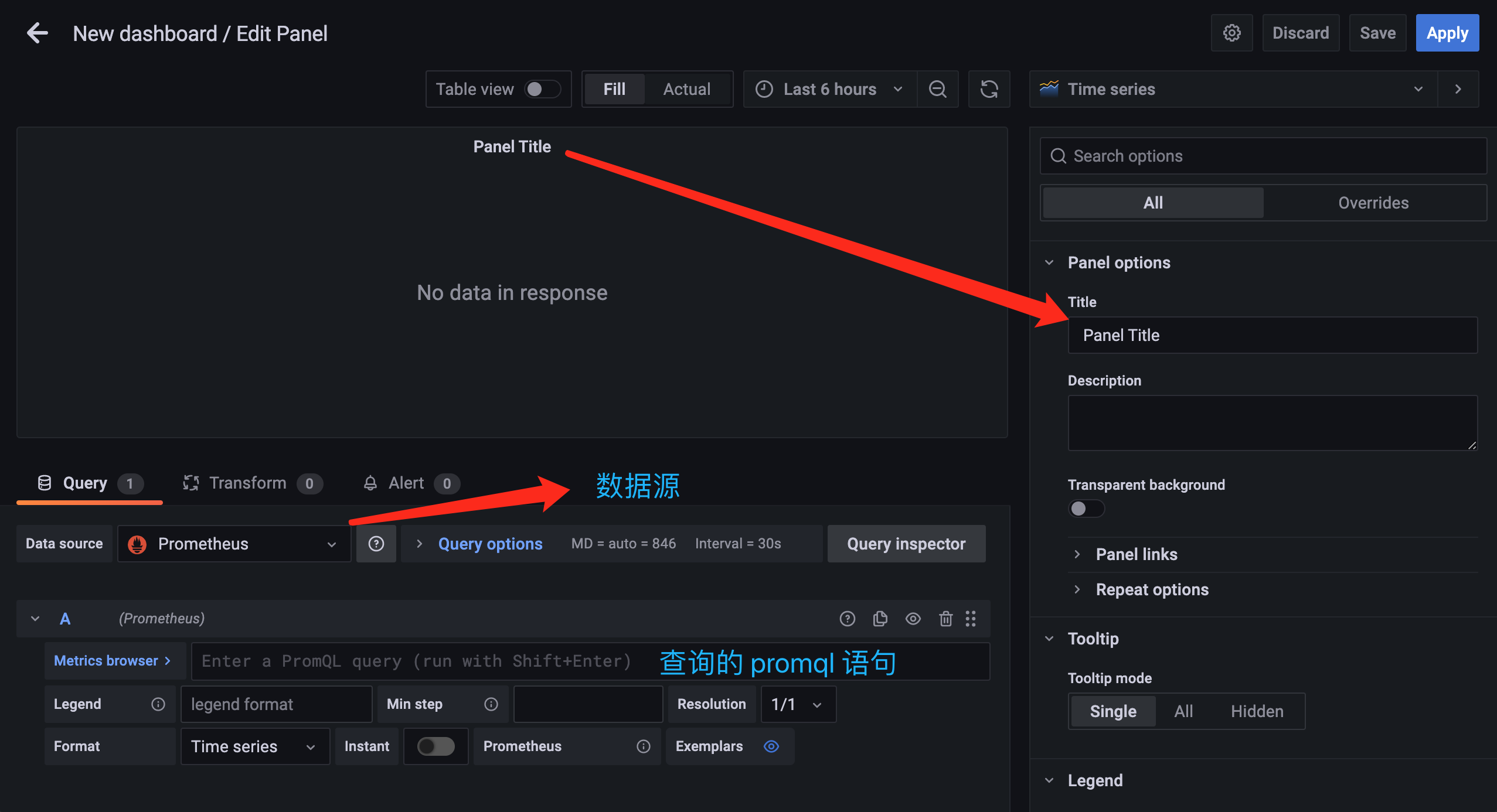
比如我们现在就要来查询节点的 CPU 使用率,前面在 node_exporter 章节中已经学习了该监控数据的查询语句为 (1 - sum(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) / sum(rate(node_cpu_seconds_total[5m])) by (instance) ) * 100,只需要将该语句填充到查询的 PromQL 语句中即可在上面显示出监控的结果:
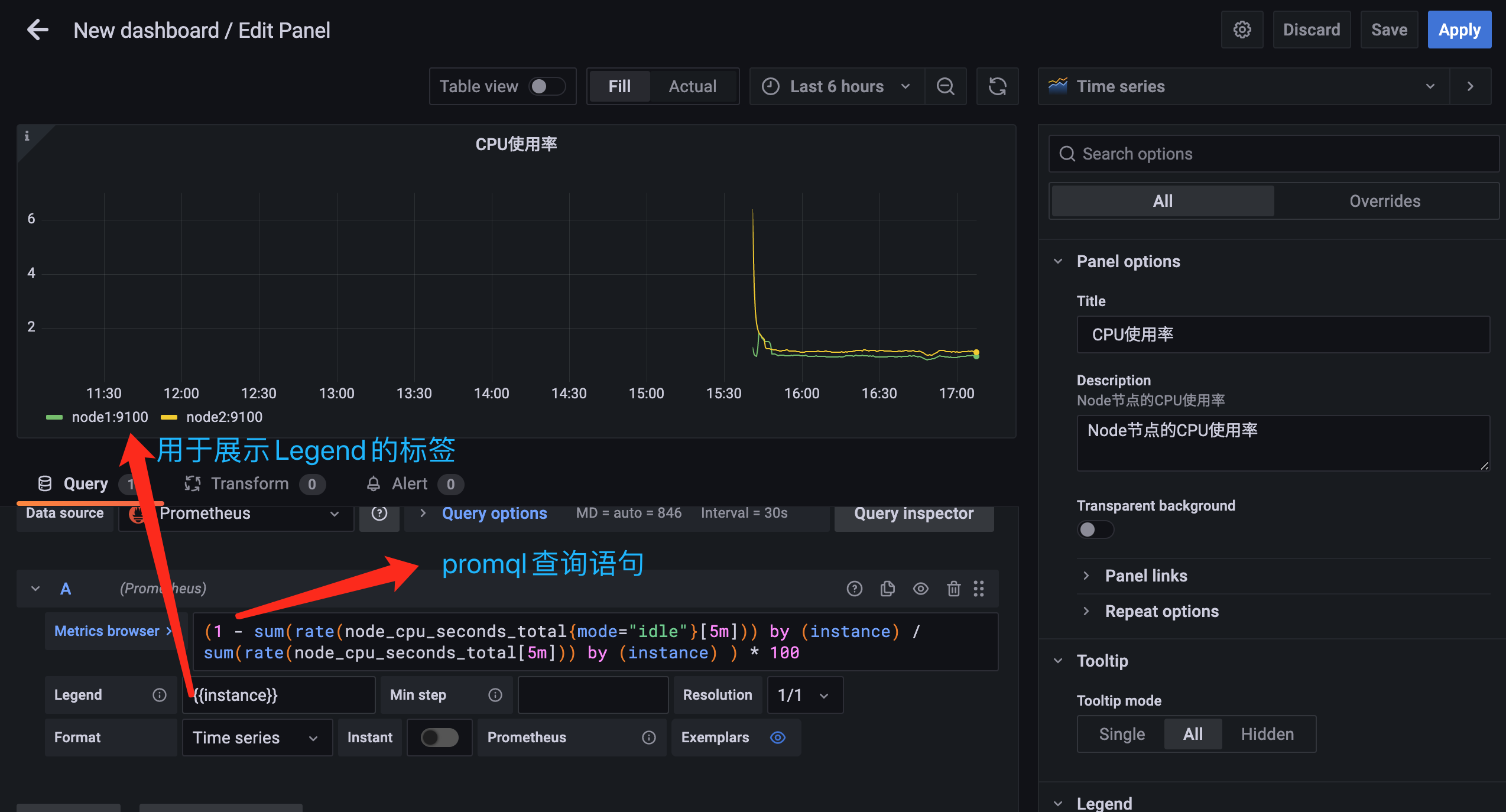
点击右上角的 Apply 按钮即可创建成功一个 Panel 面板。
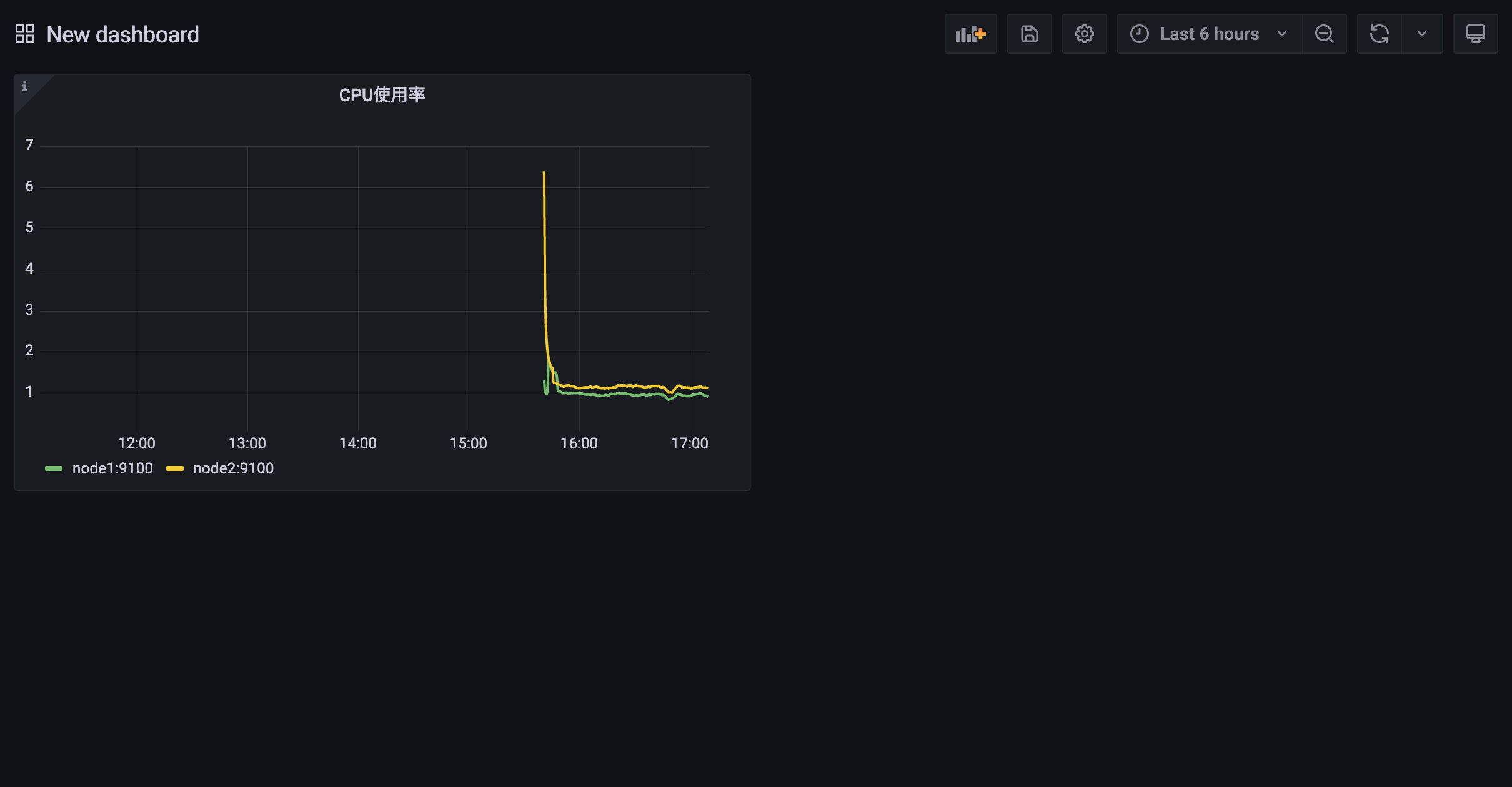
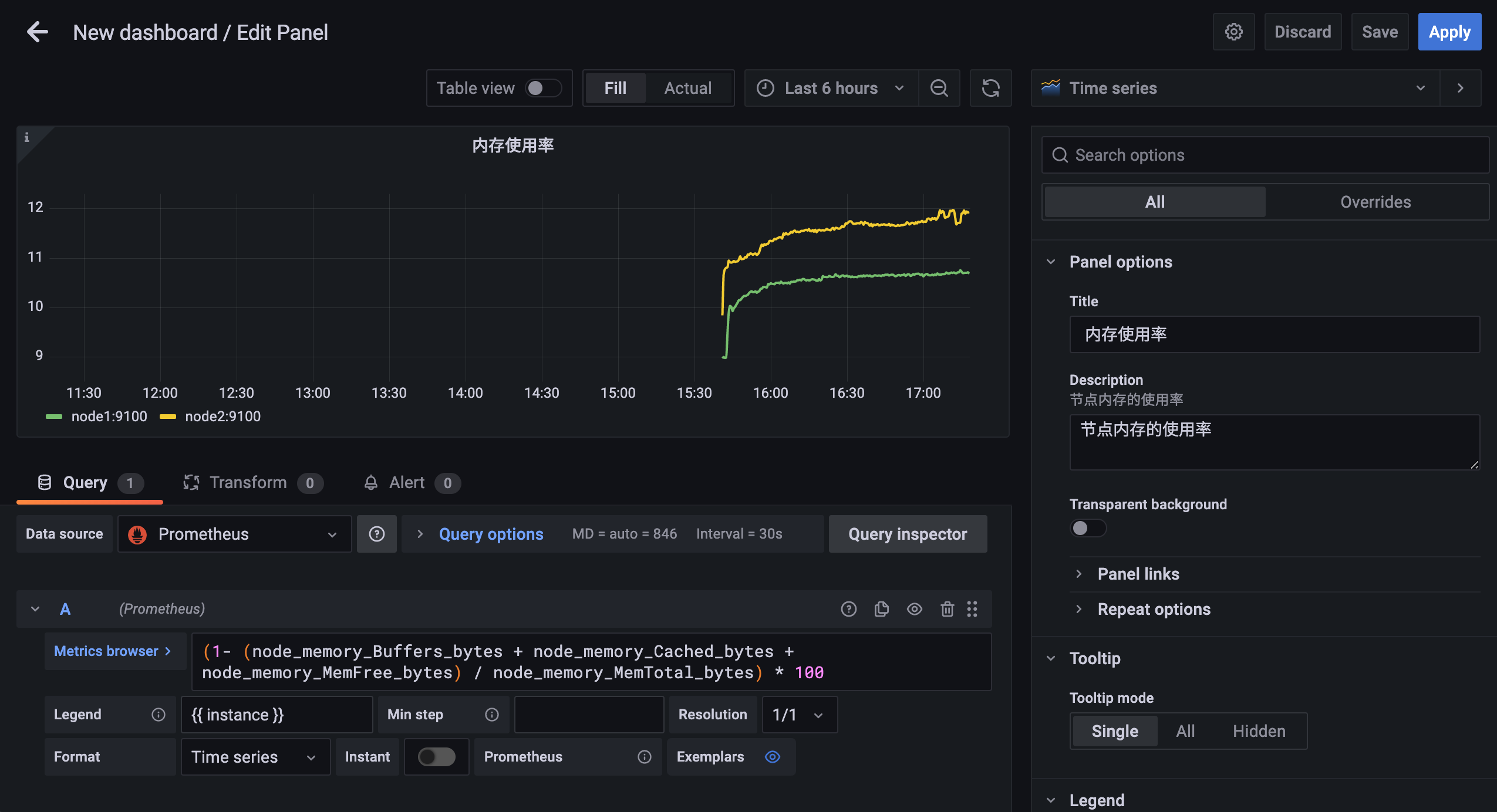
用同样的方式我们可以创建一个用于查询节点内存使用率的面板:
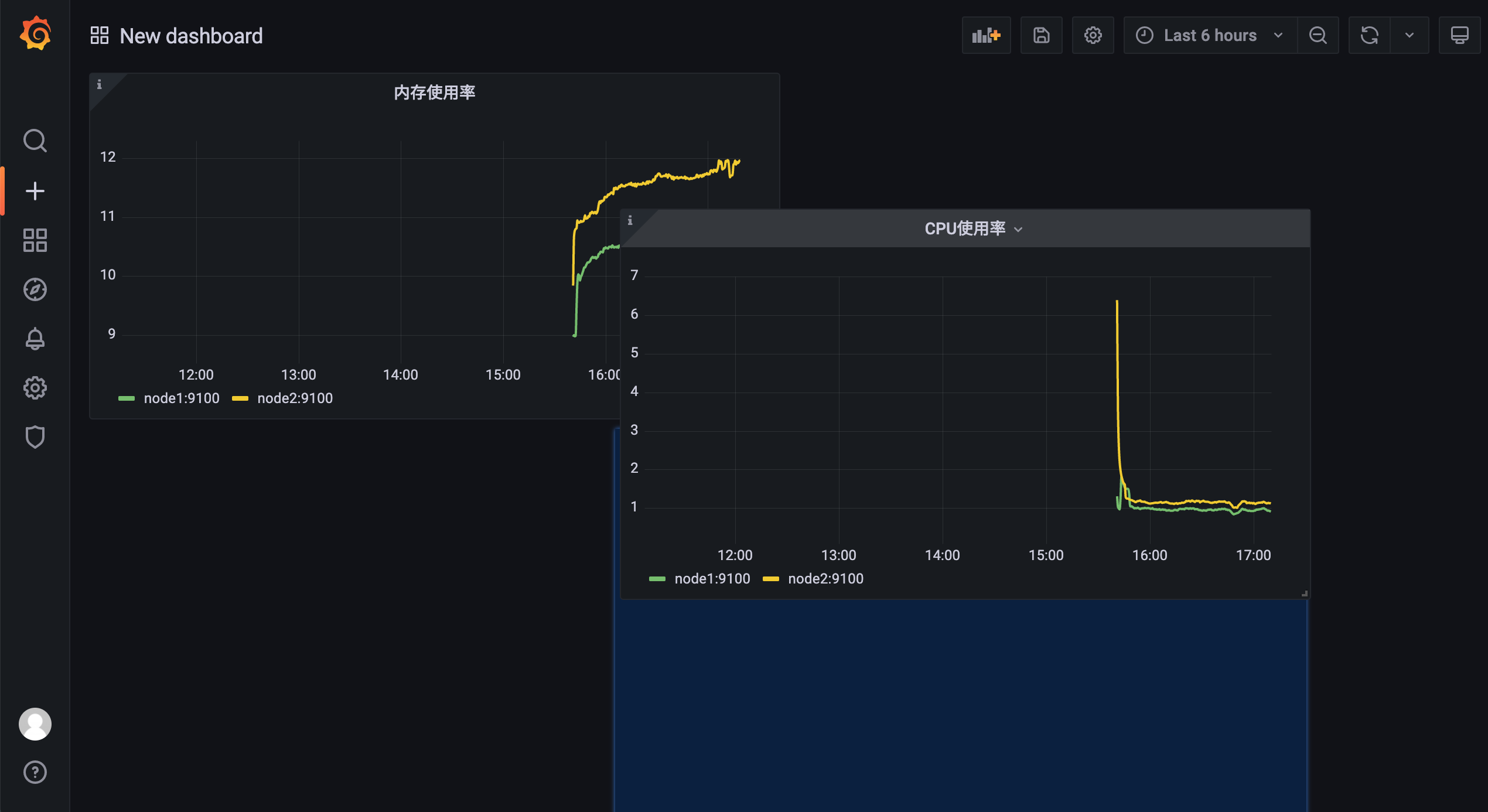
创建完成后的面板我们也可以拖动他们的排列位置:
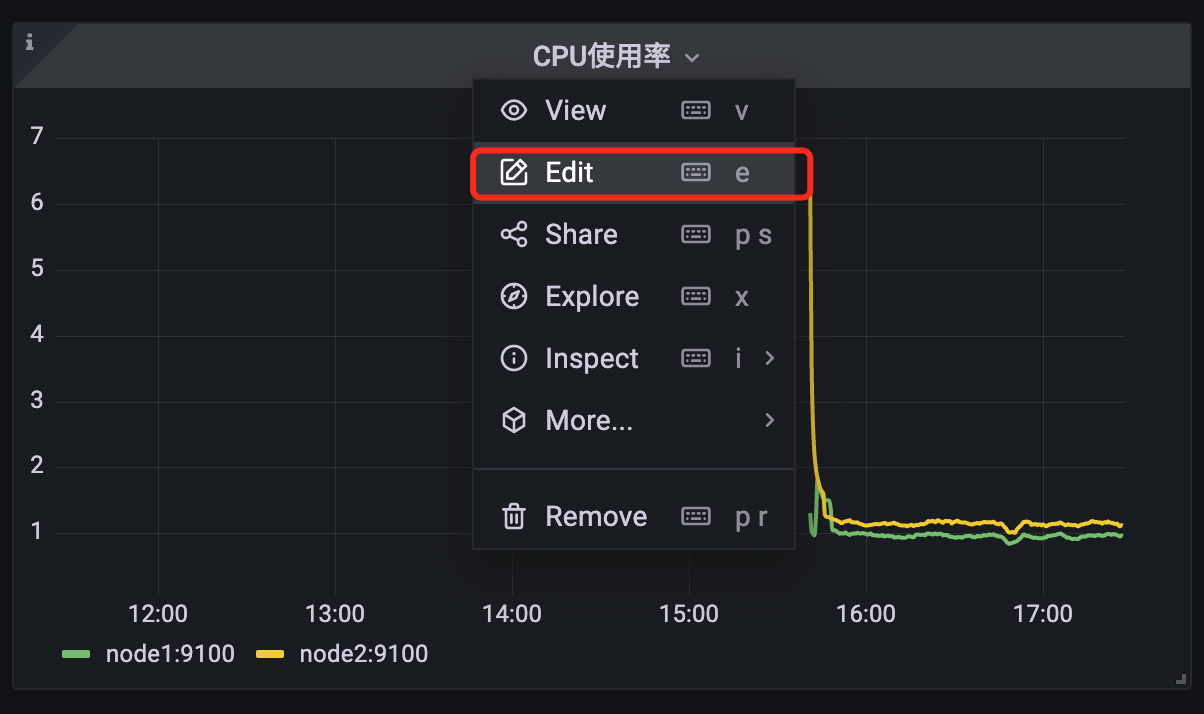
如果还想重新编辑面板,可以点击标题,在弹出来的下拉框中选择 Edit 编辑即可:
添加参数
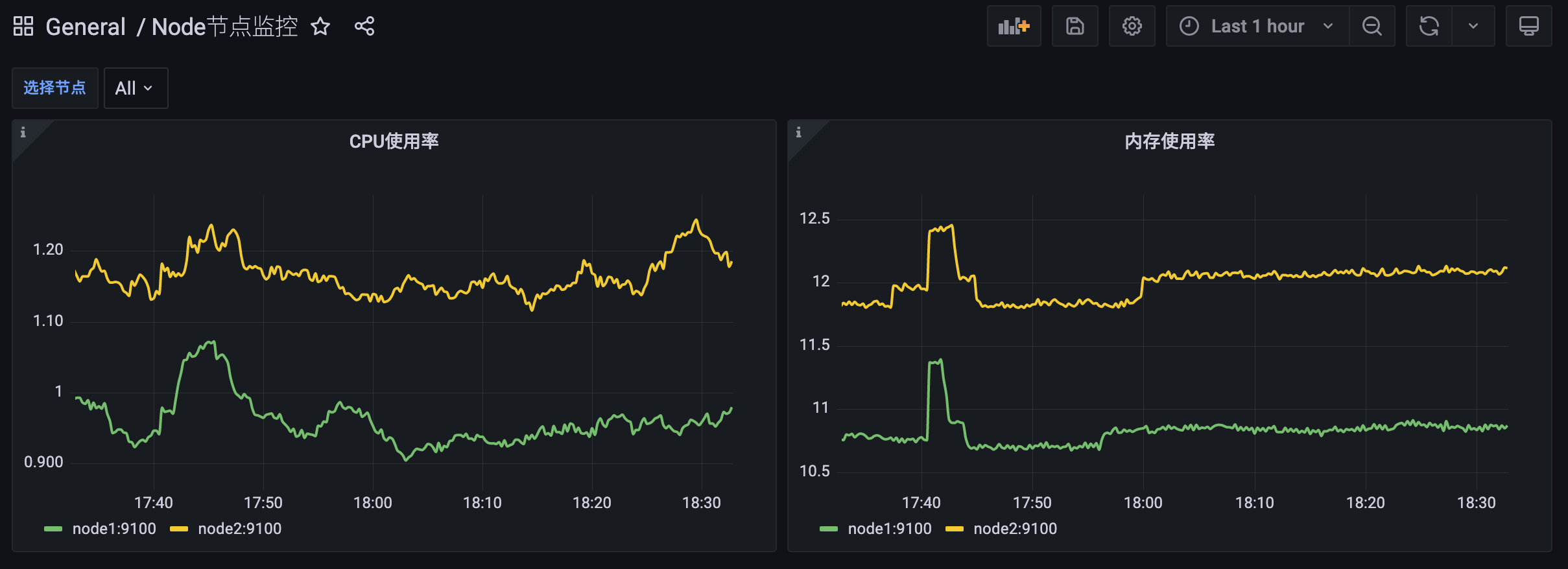
现在我们在一个 Dashboard 中添加了两个 Panel,我们可以很明显看到会直接将所有的节点信息展示在同一个面板中,但是如果有非常多的节点的话数据量就非常大了,这种情况下我们最好的方式是将节点当成参数,可以让用户自己去选择要查看哪一个节点的监控信息,要实现这个功能,我们就需要去添加一个以节点为参数的变量来去查询监控数据。
点击 Dashboard 页面右上方的 Dashboard settings 按钮,进入配置页面:
在该 Settings 页面可以来对整个 Dashboard 进行配置,比如名称、标签、变量等:
这里我们点击左边的 Variables 添加一个变量,变量支持更具交互性和动态性的仪表板,我们可以在它们的位置使用变量,而不是在指标查询中硬编码,变量显示为 Dashboard 顶部的下拉列表,这些下拉列表可以轻松更改仪表板中显示的数据。
为了能够选择节点数据,这里我们定义了一个名为 instance 的变量名,在添加变量的页面中主要包括如下一些属性:
Name:变量名,在仪表盘中调用使用$变量名的方式Type:变量类型,变量类型有多种,其中query表示这个变量是一个查询语句Hide:为空是表现为下拉框,选择 label 表示不显示下拉框的名字,选择 variable 表示隐藏该变量,该变量不会在 Dashboard 上方显示出来,默认选择为空Data source:查询语句的数据源Refresh:何时去更新变量的值,变量的值是通过查询数据源获取到的,但是数据源本身也会发生变化,所以要时不时的去更新变量的值,这样数据源的改变才会在变量对应的下拉框中显示出来。Refresh 有两个值可以选择:On Dashboard Load(在 Dashboard 加载时更新)、On Time Range Change(在时间范围变更的时候更新)Query:查询表达式,不同的数据源查询表达式都不同Regex:正则表达式,用来对抓取到的数据进行过滤,默认不过滤Sort:排序,对下拉框中的变量值做排序,默认是 disable,表示查询结果是怎样下拉框就怎样显示Multi-value:启用这个功能,变量的值就可以选择多个,具体表现在变量对应的下拉框中可以选多个值的组合Include All option:启用这个功能,变量下拉框中就多了一个全选 all 的选项
但是定义的这个变量值从哪个地方获取呢?
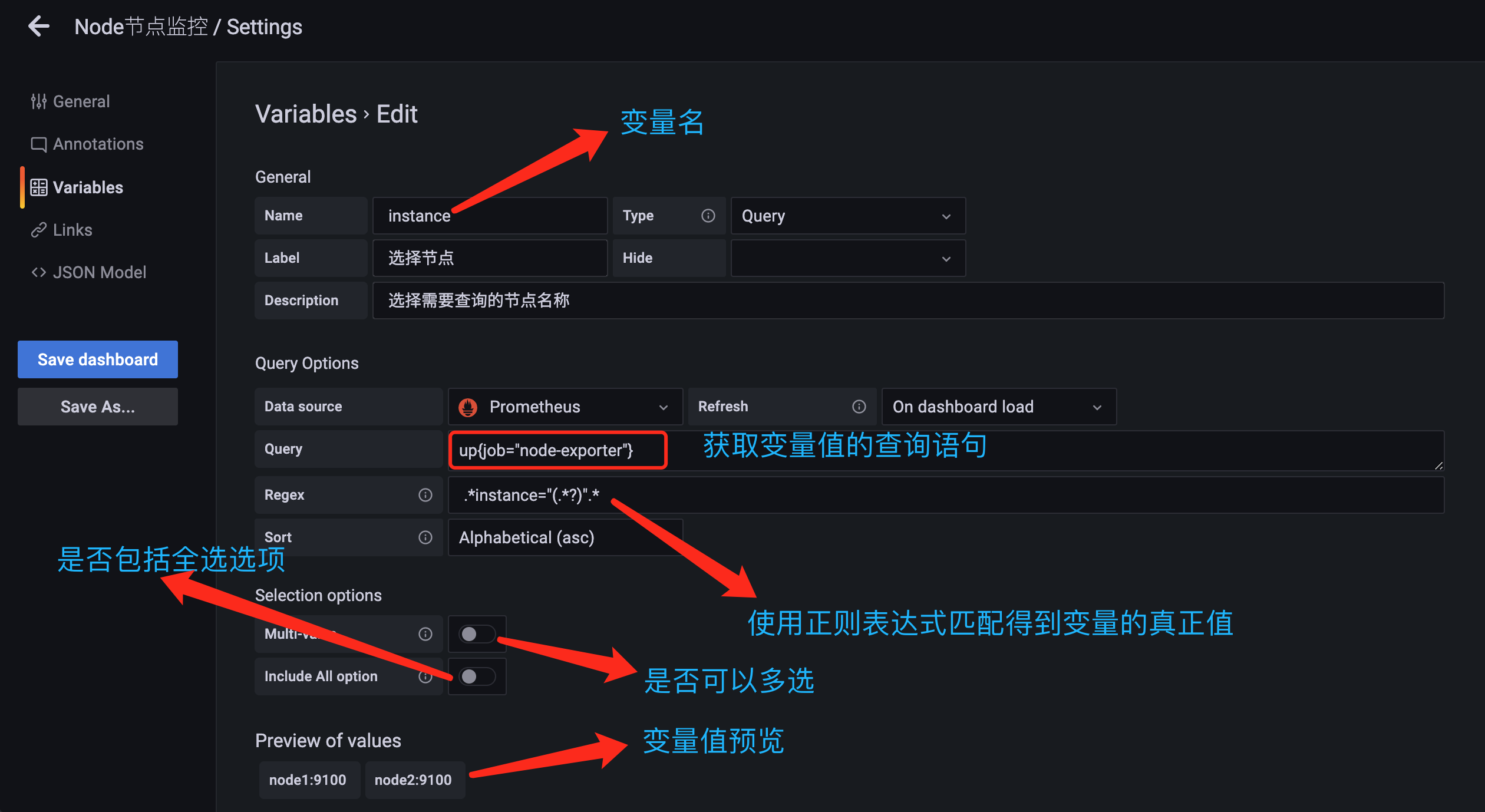
监控节点的相关指标是来源于名为 node-exporter 的任务,我们可以通过查询 up 来获取所有的监控实例:

要想获取到 instance 标签中的值,我们这里可以使用一个正则表达式 .*instance="(.*?)".* 来获取实例数据,这样就成功定义了一个变量,除了使用正则表达式的方式来获取需要的值,此外我们还可以使用一个 label_values() 的函数来直接获取查询结果中的某个 label 标签的值:
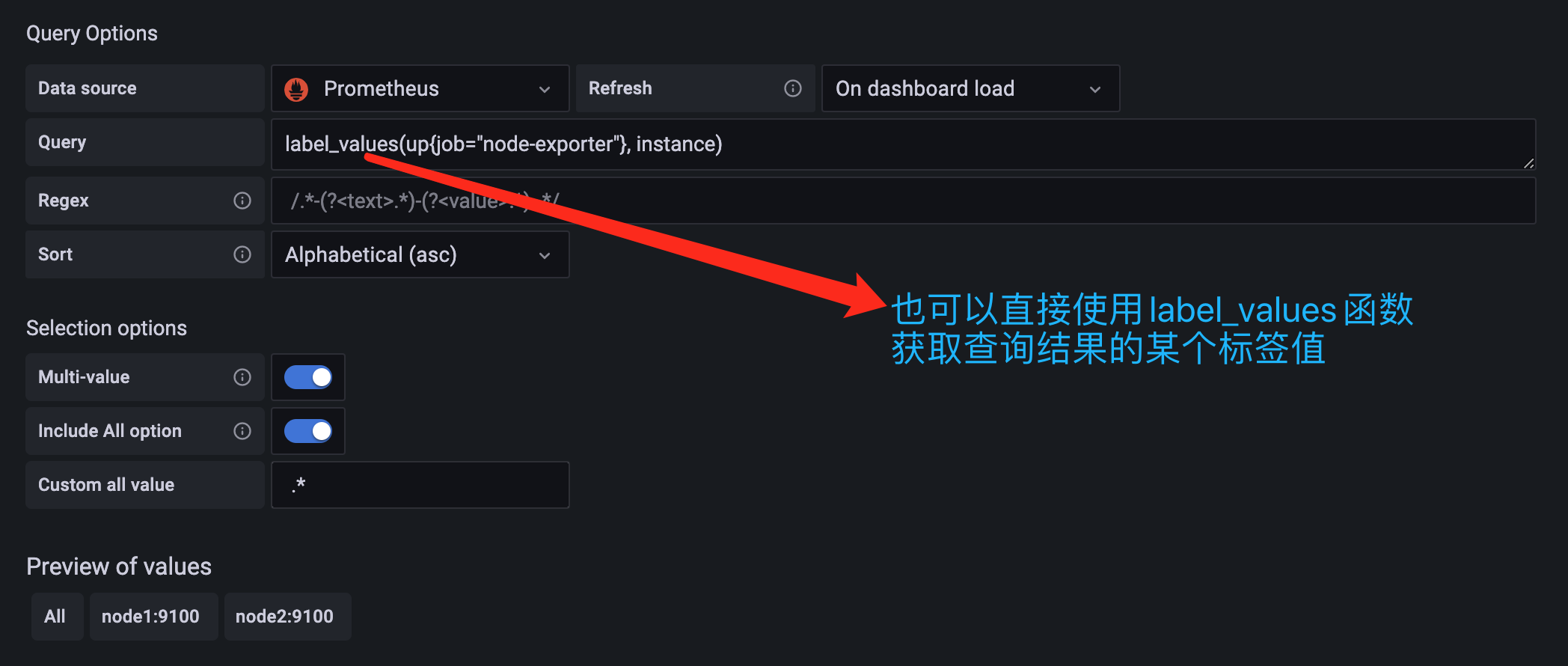
回到 Dashboard 页面就可以看到多了一个选择节点的下拉框:
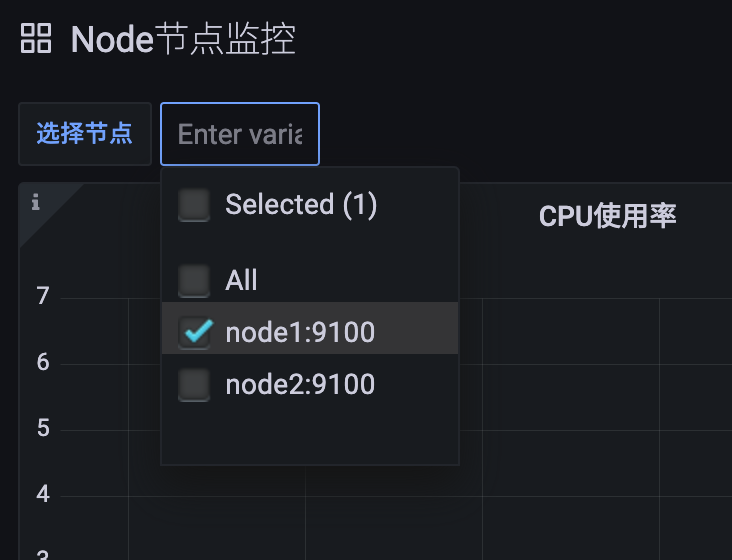
但是这个时候的面板并不会随着我们下拉框的选择而变化,我们需要将 instance 这个变量传入查询语句中,比如重新修改CPU使用率的查询语句:
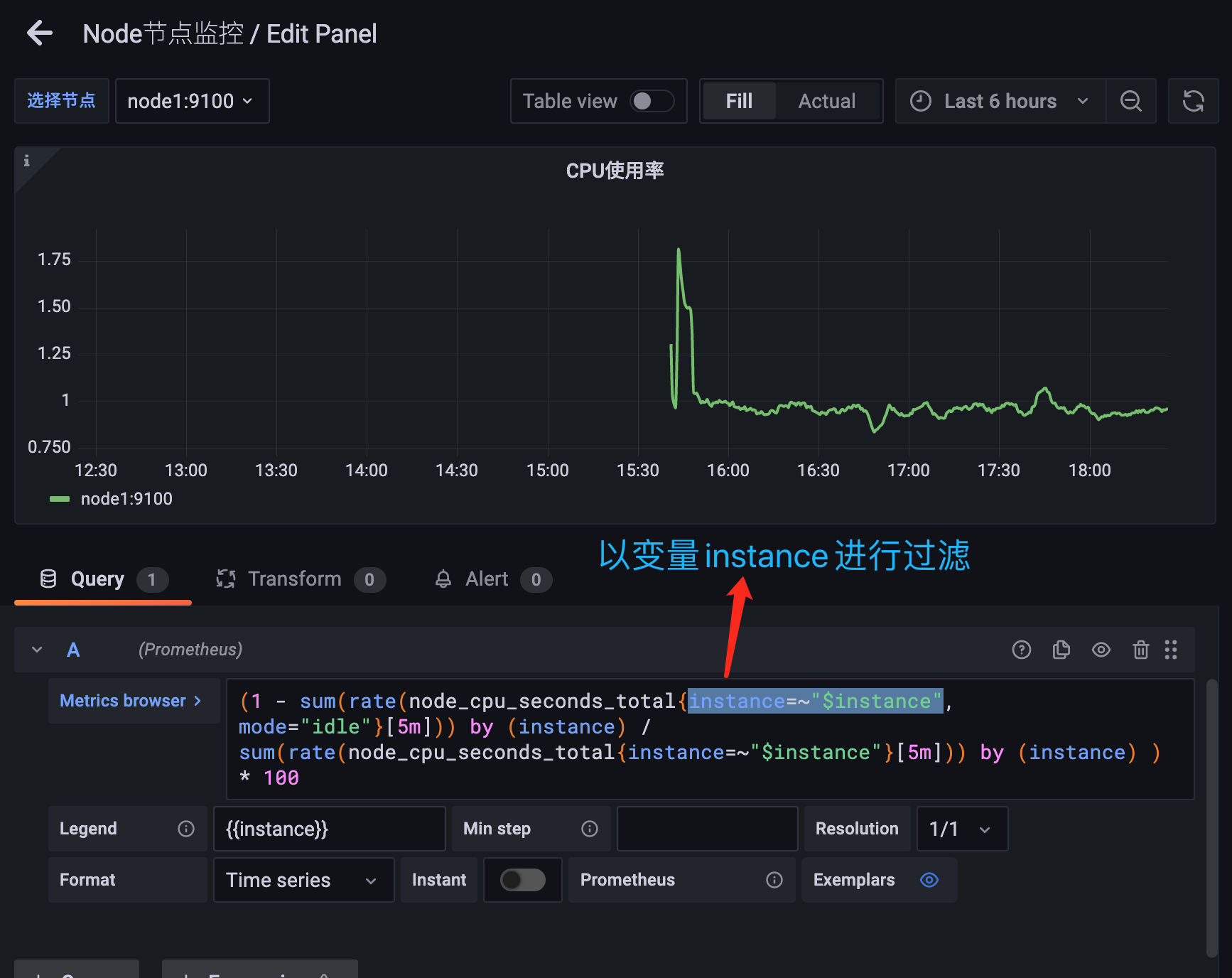
用同样的方式给内存使用率添加根据节点过滤的参数:
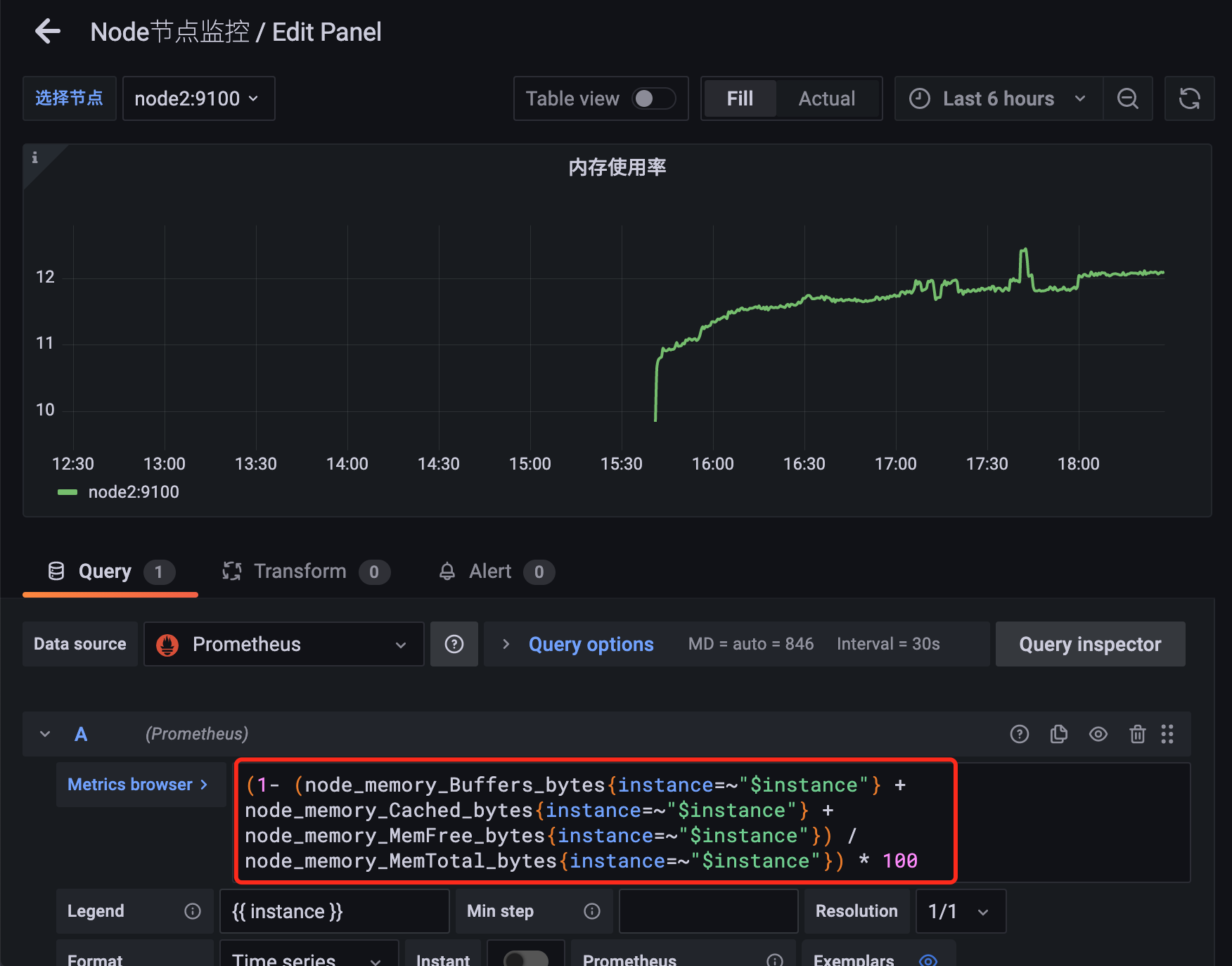
回到 Dashboard 页面就可以根据我们的下拉框来选择需要监控的节点数据了,定义参数的时候如果选择了可以选择所有,同样可以查看所有节点的数据: