直方图
在这一节中,我们将学习直方图指标,了解如何根据这些指标来计算分位数。Prometheus 中的直方图指标允许一个服务记录一系列数值的分布。直方图通常用于跟踪请求的延迟或响应大小等指标值,当然理论上它是可以跟踪任何根据某种分布而产生波动数值的大小。Prometheus 直方图是在客户端对数据进行的采样,它们使用的一些可配置的(例如延迟)bucket 桶对观察到的值进行计数,然后将这些 bucket 作为单独的时间序列暴露出来。
下图是一个非累积直方图的例子:
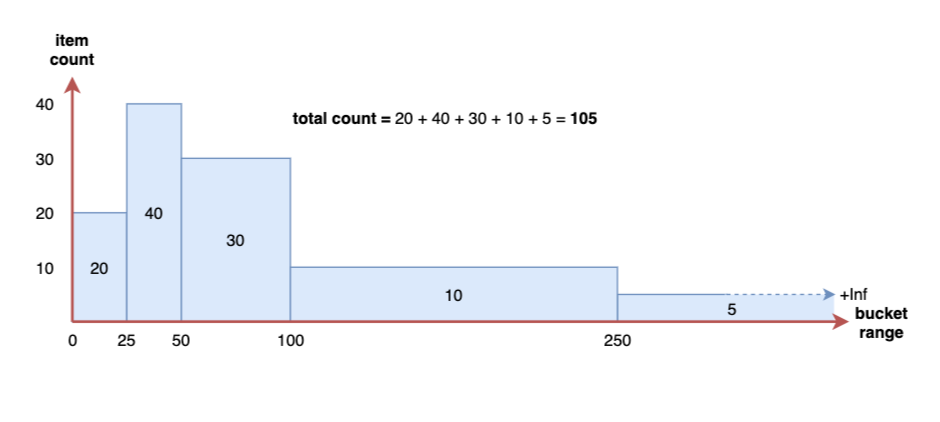
在 Prometheus 内部,直方图被实现为一组时间序列,每个序列代表指定桶的计数(例如10ms以下的请求数、25ms以下的请求数、50ms以下的请求数等)。 在 Prometheus 中每个 bucket 桶的计数器是累加的,这意味着较大值的桶也包括所有低数值的桶的计数。在作为直方图一部分的每个时间序列上,相应的桶由特殊的 le 标签表示。le 代表的是小于或等于。
与上面相同的直方图在 Prometheus 中的累积直方图如下所示:
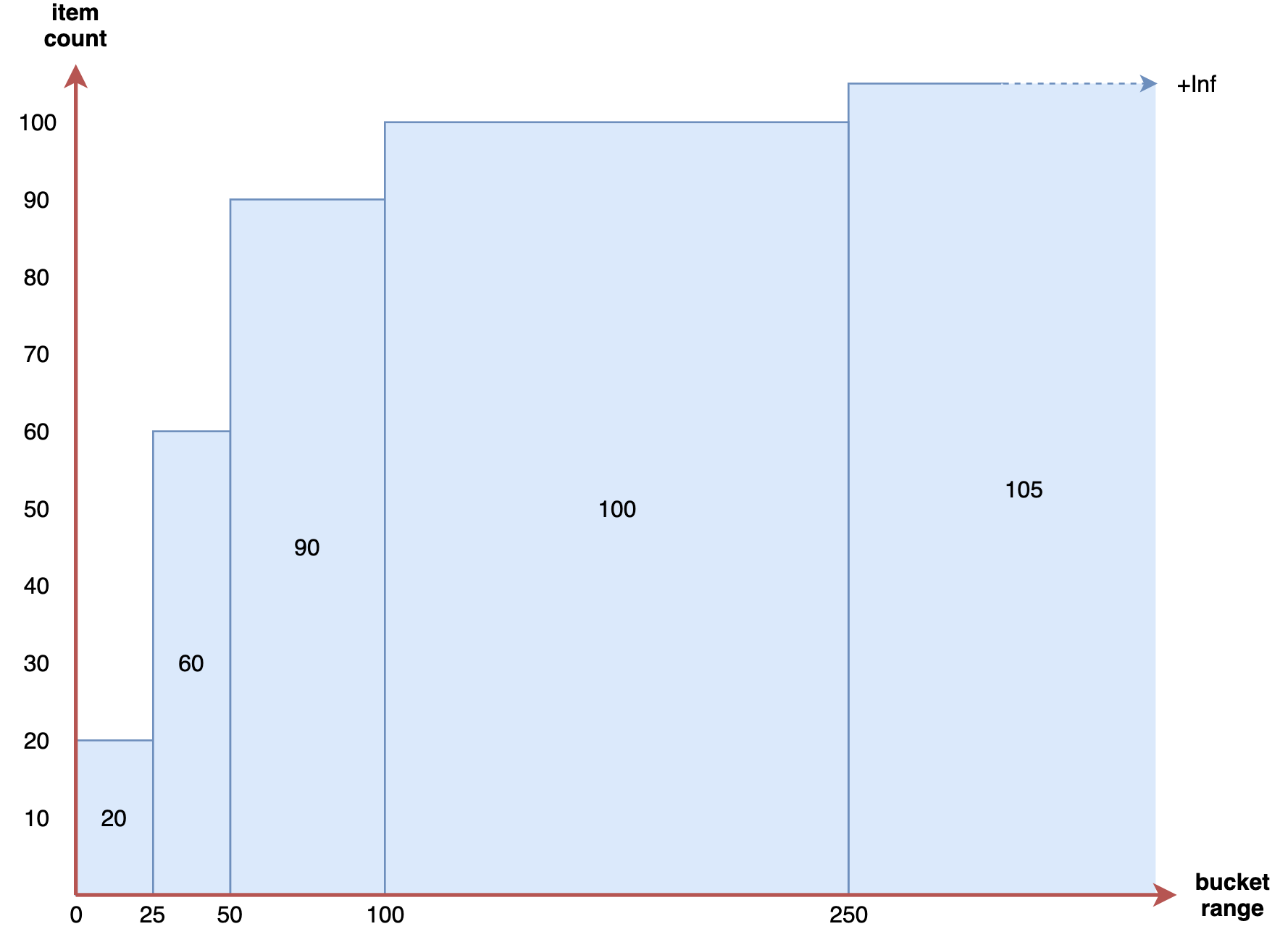
可以看到在 Prometheus 中直方图的计数是累计的,这是很奇怪的,因为通常情况下非累积的直方图更容易理解。Prometheus 为什么要这么做呢?想象一下,如果直方图指标中加入了额外的标签,或者划分了更多的 bucket,那么样本数据的分析就会变得越来越复杂,如果直方图是累积的,在抓取指标时就可以根据需要丢弃某些 bucket,这样可以在降低 Prometheus 维护成本的同时,还可以粗略计算样本值的分位数。通过这种方法,用户不需要修改应用代码,便可以动态减少抓取到的样本数量。另外直方图还提供了 _sum 指标和 _count 指标,所以即使你丢弃了所有的 bucket,仍然可以通过这两个指标值来计算请求的平均响应时间。通过累积直方图的方式,还可以很轻松地计算某个 bucket 的样本数占所有样本数的比例。
我们在演示的 demo 服务中暴露了一个直方图指标 demo_api_request_duration_seconds_bucket,用于跟踪 API 请求时长的分布,由于这个直方图为每个跟踪的维度导出了 26 个 bucket,因此这个指标有很多时间序列。我们可以先来看下来自一个服务实例的一个请求维度组合的直方图,查询语句如下所示:
demo_api_request_duration_seconds_bucket{instance="demo-service-0:10000", method="POST", path="/api/bar", status="200", job="demo"}
正常我们可以看到 26 个序列,每个序列代表一个 bucket,由 le 标签标识:
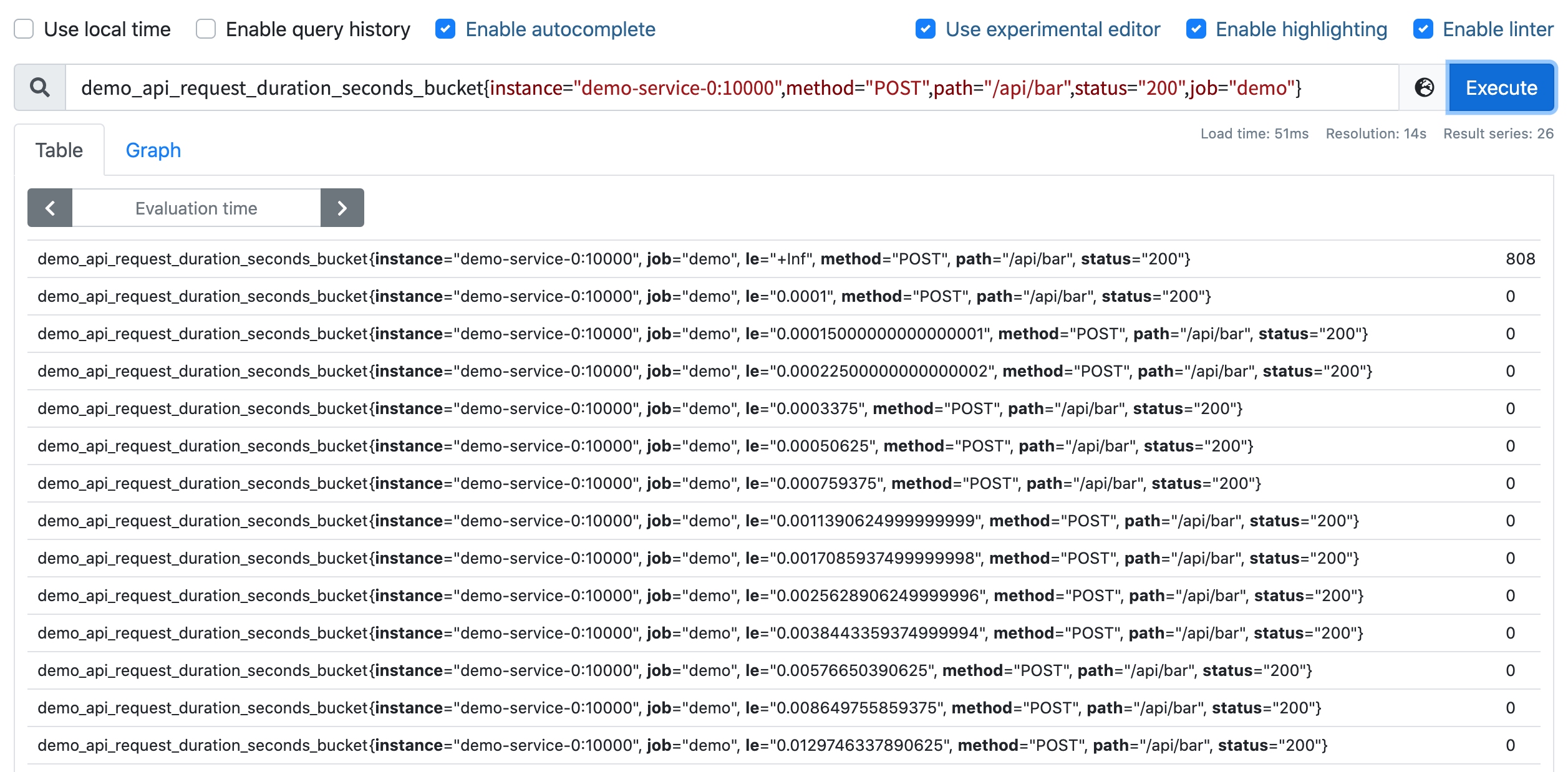
直方图可以帮助我们了解这样的问题,比如"我有多少个请求超过了100ms的时间?" (当然需要直方图中配置了一个以 100ms 为边界的桶),又比如"我99%的请求是在多少延迟下完成的?",这类数值被称为百分位数或分位数。在 Prometheus 中这两个术语几乎是可以通用,只是百分位数指定在 0-100 范围内,而分位数表示在 0 和 1 之间,所以第 99 个百分位数相当于目标分位数 0.99。
如果你的直方图桶粒度足够小,那么我们可以使用 histogram_quantile(φ scalar, b instant-vector) 函数用于计算历史数据指标一段时间内的分位数。该函数将目标分位数 (0 ≤ φ ≤ 1) 和直方图指标作为输入,就是大家平时讲的 pxx,p50 就是中位数,参数 b 一定是包含 le 这个标签的瞬时向量,不包含就无从计算分位数了,但是计算的分位数是一个预估值,并不完全准确,因为这个函数是假定每个区间内的样本分布是线性分布来计算结果值的,预估的准确度取决于 bucket 区间划分的粒度,粒度越大,准确度越低。
回到我们的演示服务,我们可以尝试计算所有维度在所有时间内的第 90 个百分位数,也就是 90% 的请求的持续时间。
# BAD!
histogram_quantile(0.9, demo_api_request_duration_seconds_bucket{job="demo"})
但是这个查询方式是有一点问题的,当单个服务实例重新启动时,bucket 的 Counter 计数器会被重置,而且我们常常想看看现在的延迟是多少(比如在过去 5 分钟内),而不是整个时间内的指标。我们可以使用 rate() 函数应用于底层直方图计数器来实现这一点,该函数会自动处理 Counter 重置,又可以只计算每个桶在指定时间窗口内的平均增长。
我们可以这样去计算过去 5 分钟内第 90 个百分位数的 API 延迟:
# GOOD!
histogram_quantile(0.9, rate(demo_api_request_duration_seconds_bucket{job="demo"}[5m]))
这个查询就好很多了。
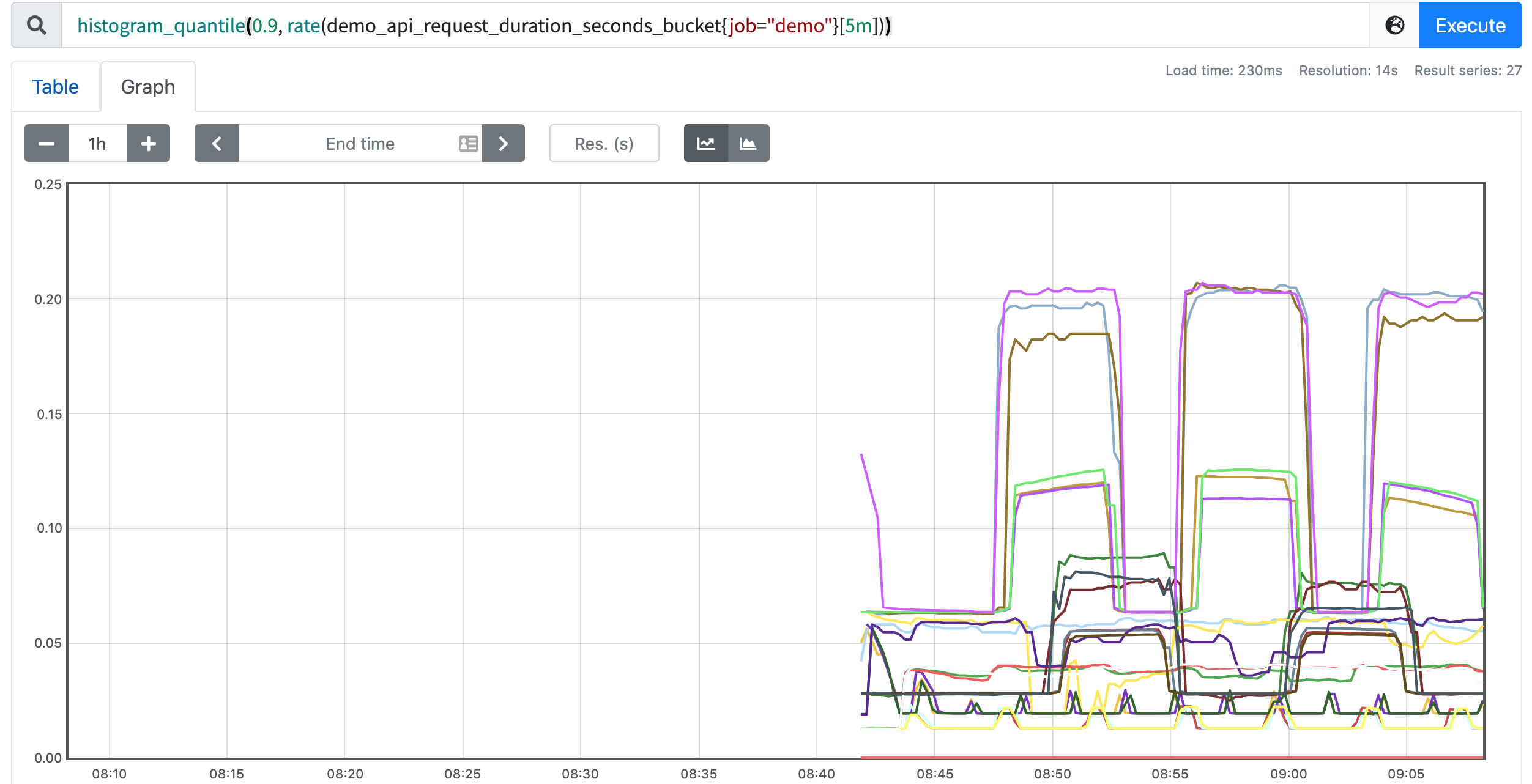
这个查询会显示每个维度(job、instance、path、method 和 status)的第 90 个百分点,但是我们可能对单独的这些维度并不感兴趣,想把他们中的一些指标聚合起来,这个时候我们可以在查询的时候使用 Prometheus 的 sum 运算符与 histogram_quantile() 函数结合起来,计算出聚合的百分位,假设在我们想要聚合的维度之间,直方图桶的配置方式相同(桶的数量相同,上限相同),我们可以将不同维度之间具有相同 le 标签值的桶加在一起,得到一个聚合直方图。然后,我们可以使用该聚合直方图作为 histogram_quantile() 函数的输入。
注意:这是假设直方图的桶在你要聚合的所有维度之间的配置是相同的,桶的配置也应该是相对静态的配置,不会一直变化,因为这会破坏你使用
histogram_quantile()查看的时间范围内的结果。
下面的查询计算了第 90 个百分位数的延迟,但只按 job、instance 和 path 维度进行聚合结果:

练习
1.构建一个查询,计算在 0.0001 秒内完成的 demo 服务 API 请求的总百分比,与过去 5 分钟内所有请求总数的平均值。
sum(rate(demo_api_request_duration_seconds_bucket{le="0.0001"}[5m]))
/
sum(rate(demo_api_request_duration_seconds_bucket{le="+Inf"}[5m])) * 100
或者可以使用下面的语句查询
sum(rate(demo_api_request_duration_seconds_bucket{le="0.0001"}[5m]))
/
sum(rate(demo_api_request_duration_seconds_count[5m])) * 100
2.构建一个查询,计算 demo 服务 API 请求的第 50 个百分位延迟,按 status code 和 method 进行划分,在过去一分钟的平均值。
histogram_quantile(0.5, sum by(status, method, le) (rate(demo_api_request_duration_seconds_bucket[1m])))